分区扩容源码解析
kafka管控推荐使用 滴滴开源 的 Kafka运维管控平台 更符合国人的操作习惯 ,
更强大的管控能力 ,更高效的问题定位能力 、更便捷的集群运维能力 、更专业的资源治理 、 更友好的运维生态
脚本参数
sh bin/kafka-topic -help 查看更具体参数
下面只是列出了跟 --alter 相关的参数
| 参数 | 描述 | 例子 |
|---|---|---|
--bootstrap-server 指定kafka服务 |
指定连接到的kafka服务; 如果有这个参数,则 --zookeeper可以不需要 |
–bootstrap-server localhost:9092 |
--replica-assignment |
副本分区分配方式;修改topic的时候可以自己指定副本分配情况; | --replica-assignment id0:id1:id2,id3:id4:id5,id6:id7:id8 ;其中,“id0:id1:id2,id3:id4:id5,id6:id7:id8”表示Topic TopicName一共有3个Partition(以“,”分隔),每个Partition均有3个Replica(以“:”分隔),Topic Partition Replica与Kafka Broker之间的对应关系如下:1278 |
--topic |
||
--partitions |
扩展到新的分区数 |
Alert Topic脚本
分区扩容
zk方式(不推荐)
1 | bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic1 --partitions 2 |
kafka版本 >= 2.2 支持下面方式(推荐)
单个Topic扩容
bin/kafka-topics.sh --bootstrap-server broker_host:port --alter --topic test_create_topic1 --partitions 4
批量扩容 (将所有正则表达式匹配到的Topic分区扩容到4个)
sh bin/kafka-topics.sh --topic ".*?" --bootstrap-server 172.23.248.85:9092 --alter --partitions 4
".*?"正则表达式的意思是匹配所有; 您可按需匹配
PS: 当某个Topic的分区少于指定的分区数时候,他会抛出异常;但是不会影响其他Topic正常进行;
相关可选参数
| 参数 | 描述 | 例子 |
|---|---|---|
--replica-assignment |
副本分区分配方式;创建topic的时候可以自己指定副本分配情况; | --replica-assignment BrokerId-0:BrokerId-1:BrokerId-2,BrokerId-1:BrokerId-2:BrokerId-0,BrokerId-2:BrokerId-1:BrokerId-0 ; 这个意思是有三个分区和三个副本,对应分配的Broker; 逗号隔开标识分区;冒号隔开表示副本 |
PS: 虽然这里配置的是全部的分区副本分配配置,但是真正生效的是新增的分区;
比如: 以前3分区1副本是这样的
| Broker-1 | Broker-2 | Broker-3 | Broker-4 |
|---|---|---|---|
| 0 | 1 | 2 |
现在新增一个分区,--replica-assignment 2,1,3,4 ; 看这个意思好像是把0,1号分区互相换个Broker
| Broker-1 | Broker-2 | Broker-3 | Broker-4 |
|---|---|---|---|
| 1 | 0 | 2 | 3 |
但是实际上不会这样做,Controller在处理的时候会把前面3个截掉; 只取新增的分区分配方式,原来的还是不会变
| Broker-1 | Broker-2 | Broker-3 | Broker-4 |
|---|---|---|---|
| 0 | 1 | 2 | 3 |
源码解析
如果觉得源码解析过程比较枯燥乏味,可以直接如果 源码总结及其后面部分
因为在 【kafka源码】TopicCommand之创建Topic源码解析 里面分析的比较详细; 故本文就着重点分析了;
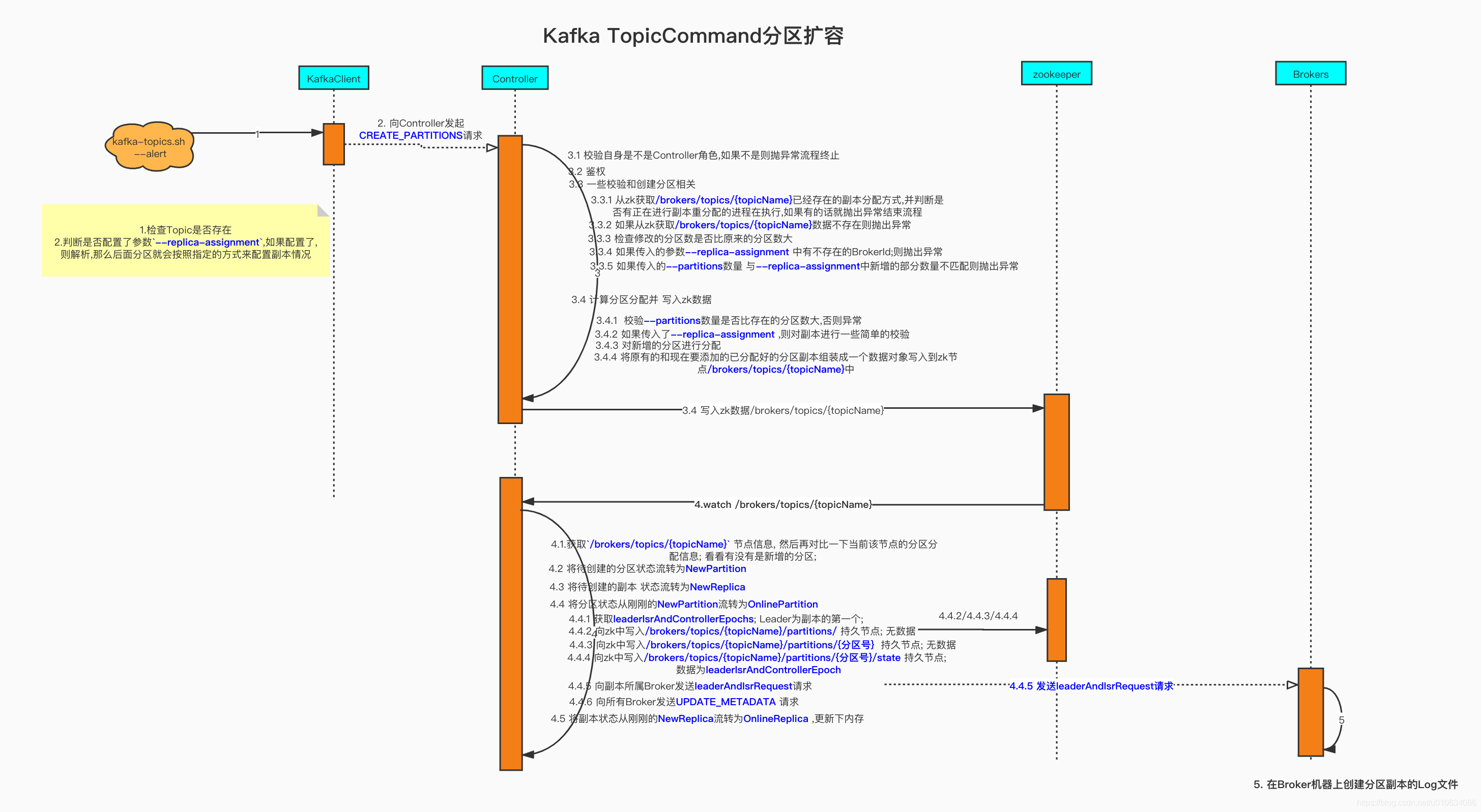
1. TopicCommand.alterTopic
1 | override def alterTopic(opts: TopicCommandOptions): Unit = { |
- 校验Topic是否存在
- 如果设置了
--replica-assignment参数, 则会算出新增的分区数的分配; 这个并不会修改原本已经分配好的分区结构.从源码就可以看出来,假如我之前的分配方式是3,3,3(3分区一个副本都在BrokerId-3上)现在我传入的参数是:3,3,3,3(多出来一个分区),这个时候会把原有的给截取掉;只传入3,(表示在Broker3新增一个分区)7652 - 如果没有传入参数
--replica-assignment,则后面会用默认分配策略分配
客户端发起请求createPartitions
KafkaAdminClient.createPartitions 省略部分代码
1 |
|
- 从源码中可以看到向
ControllerNodeProvider发起来createPartitions请求
2. Controller角色的服务端接受createPartitions请求处理逻辑
KafkaApis.handleCreatePartitionsRequest
1 | def handleCreatePartitionsRequest(request: RequestChannel.Request): Unit = { |
检验自身是不是Controller角色,不是的话就抛出异常终止流程
鉴权
调用
adminManager.createPartitions
3.1 从zk中获取/brokers/ids/Brokers列表的元信息的
3.2 从zk获取/brokers/topics/{topicName}已经存在的副本分配方式,并判断是否有正在进行副本重分配的进程在执行,如果有的话就抛出异常结束流程
3.3 如果从zk获取/brokers/topics/{topicName}数据不存在则抛出异常The topic '$topic' does not exist
3.4 检查修改的分区数是否比原来的分区数大,如果比原来还小或者等于原来分区数则抛出异常结束流程
3.5 如果传入的参数--replica-assignment中有不存在的BrokerId;则抛出异常Unknown broker(s) in replica assignment结束流程
3.5 如果传入的--partitions数量 与--replica-assignment中新增的部分数量不匹配则抛出异常Increasing the number of partitions by...结束流程
3.6 调用adminZkClient.addPartitions
adminZkClient.addPartitions 添加分区
- 校验
--partitions数量是否比存在的分区数大,否则异常The number of partitions for a topic can only be increased - 如果传入了
--replica-assignment,则对副本进行一些简单的校验 - 调用
AdminUtils.assignReplicasToBrokers分配副本 ; 这个我们在【kafka源码】TopicCommand之创建Topic源码解析 也分析过; 具体请看【kafka源码】创建Topic的时候是如何分区和副本的分配规则; 当然这里由于我们是新增的分区,只会将新增的分区进行分配计算 - 得到分配规则只后,调用
adminZkClient.writeTopicPartitionAssignment写入
adminZkClient.writeTopicPartitionAssignment将分区信息写入zk中
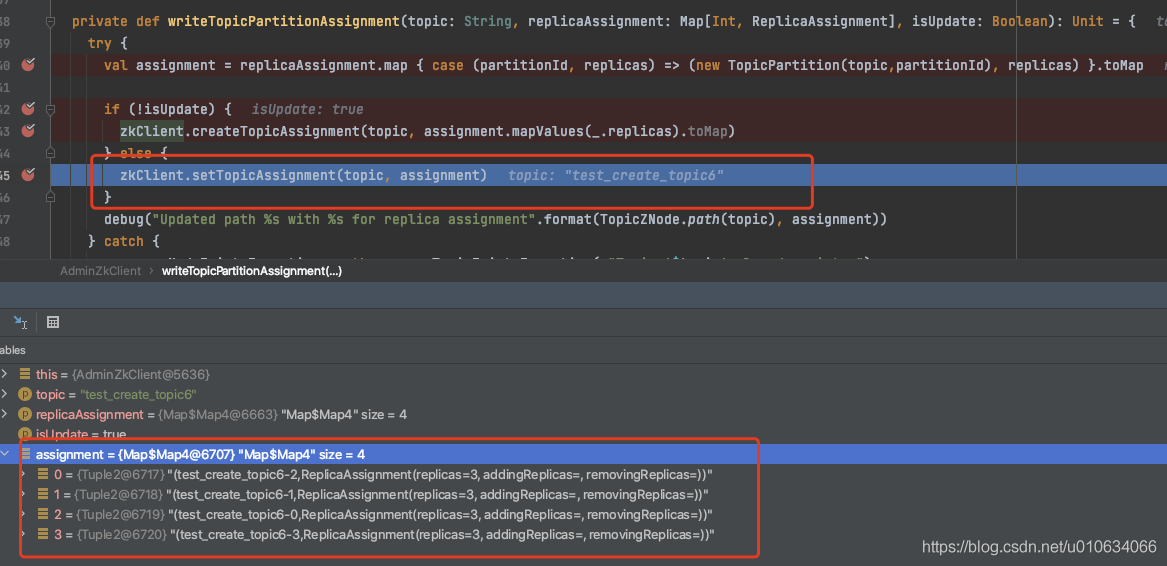
我们在 【kafka源码】TopicCommand之创建Topic源码解析的时候也分析过这段代码,但是那个时候调用的是zkClient.createTopicAssignment 创建接口
这里我们是调用 zkClient.setTopicAssignment 写入接口, 写入当然会覆盖掉原有的信息,所以写入的时候会把原来分区信息获取到,重新写入;
- 获取Topic原有分区副本分配信息
- 将原有的和现在要添加的组装成一个数据对象写入到zk节点
/brokers/topics/{topicName}中
3. Controller监控节点/brokers/topics/{topicName} ,真正在Broker上将分区写入磁盘
监听到节点信息变更之后调用下面的接口;KafkaController.processPartitionModifications
1 | private def processPartitionModifications(topic: String): Unit = { |
- 判断是否Controller,不是则直接结束流程
- 获取
/brokers/topics/{topicName}节点信息, 然后再对比一下当前该节点的分区分配信息; 看看有没有是新增的分区; 如果是新增的分区这个时候是还没有/brokers/topics/{topicName}/partitions/{分区号}/state; - 如果当前的TOPIC正在被删除中,那么就没有必要执行扩分区了
- 将新增加的分区信息加载到内存中
- 调用接口
KafkaController.onNewPartitionCreation
KafkaController.onNewPartitionCreation 新增分区
从这里开始 , 后面的流程就跟创建Topic的对应流程一样了;
该接口主要是针对新增分区和副本的一些状态流转过程; 在【kafka源码】TopicCommand之创建Topic源码解析 也同样分析过
1 | /** |
- 将待创建的分区状态流转为
NewPartition;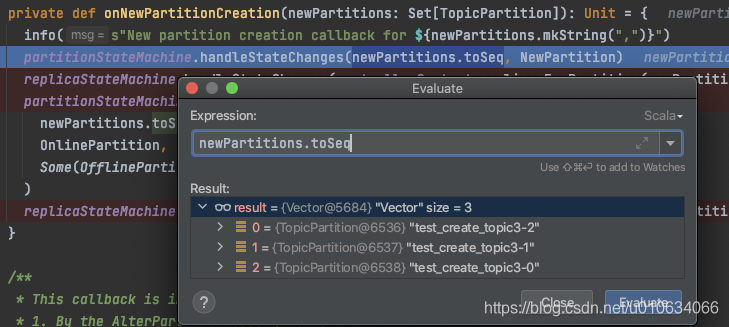
- 将待创建的副本 状态流转为
NewReplica;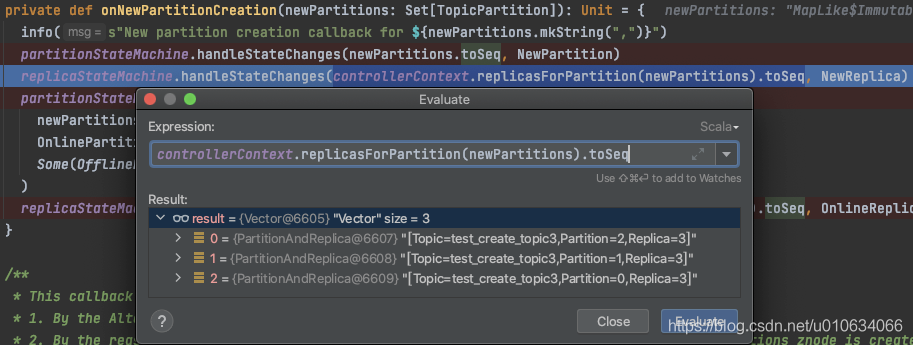
- 将分区状态从刚刚的
NewPartition流转为OnlinePartition - 获取
leaderIsrAndControllerEpochs; Leader为副本的第一个;
1. 向zk中写入/brokers/topics/{topicName}/partitions/持久节点; 无数据
2. 向zk中写入/brokers/topics/{topicName}/partitions/{分区号}持久节点; 无数据
3. 向zk中写入/brokers/topics/{topicName}/partitions/{分区号}/state持久节点; 数据为leaderIsrAndControllerEpoch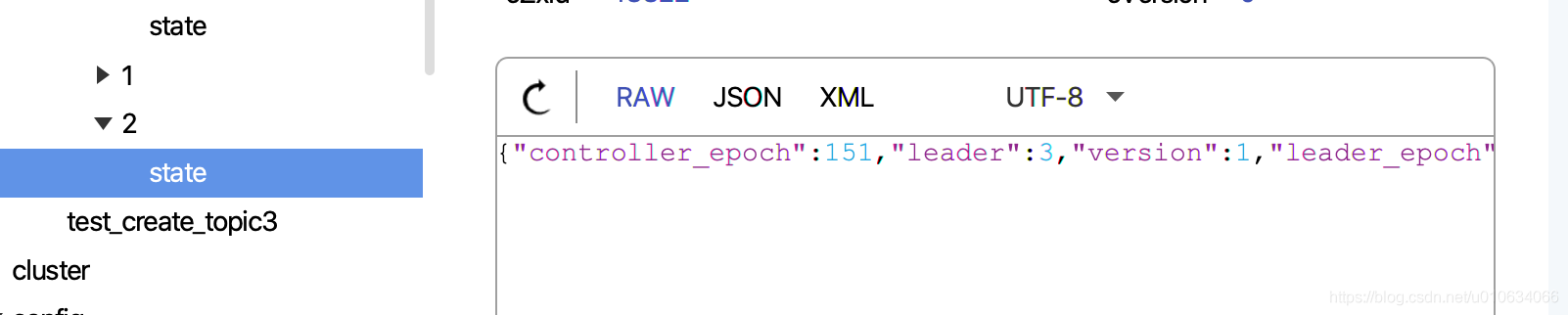
- 向副本所属Broker发送
leaderAndIsrRequest请求 - 向所有Broker发送
UPDATE_METADATA请求
- 向副本所属Broker发送
- 将副本状态从刚刚的
NewReplica流转为OnlineReplica,更新下内存
关于分区状态机和副本状态机详情请看【kafka源码】Controller中的状态机
4. Broker收到LeaderAndIsrRequest 创建本地Log
上面步骤中有说到向副本所属Broker发送
leaderAndIsrRequest请求,那么这里做了什么呢
其实主要做的是 创建本地Log代码太多,这里我们直接定位到只跟创建Topic相关的关键代码来分析
KafkaApis.handleLeaderAndIsrRequest->replicaManager.becomeLeaderOrFollower->ReplicaManager.makeLeaders...LogManager.getOrCreateLog
1 | /** |
- 如果日志已经存在,只返回现有日志的副本否则如果 isNew=true 或者如果没有离线日志目录,则为给定的主题和给定的分区创建日志 否则抛出
KafkaStorageException
详细请看 【kafka源码】LeaderAndIsrRequest请求
源码总结
看图说话
Q&A
如果自定义的分配Broker不存在会怎么样
会抛出异常
Unknown broker(s) in replica assignment, 因为在执行的时候会去zk获取当前的在线Broker列表,然后判断是否在线;
如果设置的分区数不等于 --replica-assignment中新增的数目会怎么样
会抛出异常
Increasing the number of partitions by..结束流程
如果写入/brokers/topics/{topicName}之后 Controller监听到请求正好挂掉怎么办
Controller挂掉会发生重新选举,选举成功之后, 检查到
/brokers/topics/{topicName}之后发现没有生成对应的分区,会自动执行接下来的流程;
如果我手动在zk中写入节点/brokers/topics/{topicName}/partitions/{分区号}/state 会怎么样
Controller并没有监听这个节点,所以不会有变化; 但是当Controller发生重新选举的时候,
被删除的节点会被重新添加回来;
但是写入的节点 就不会被删除了;写入的节点信息会被保存在Controller内存中;
同样这会影响到分区扩容
例子🌰:
当前分区3个,副本一个,手贱在zk上添加了一个节点如下图:
这个时候我想扩展一个分区; 然后执行了脚本, 虽然
/brokers/topics/test_create_topic3节点数据变; 但是Broker真正在LeaderAndIsrRequest请求里面没有执行创建本地Log文件; 这是因为源码读取到zk下面partitions的节点数量和新增之后的节点数量没有变更,那么它就认为本次请求没有变更就不会执行创建本地Log文件了;
如果判断有变更,还是会去创建的;
手贱zk写入N个partition节点 + 扩充N个分区 = Log文件不会被创建
手贱zk写入N个partition节点 + 扩充>N个分区 = 正常扩容
如果直接修改节点/brokers/topics/{topicName}中的配置会怎么样
如果该节点信息是
{"version":2,"partitions":{"2":[1],"1":[1],"0":[1]},"adding_replicas":{},"removing_replicas":{}}看数据,说明3个分区1个副本都在Broker-1上;
我在zk上修改成{"version":2,"partitions":{"2":[2],"1":[1],"0":[0]},"adding_replicas":{},"removing_replicas":{}}
想将分区分配到 Broker-0,Broker-1,Broker-2上
TODO。。。

 微信
微信





石臻臻的杂货铺
Java/大数据/中间件/教学视频