Controller的启动和选举流程
kafka管控推荐使用 滴滴开源 的 Kafka运维管控平台 更符合国人的操作习惯 ,
更强大的管控能力 ,更高效的问题定位能力 、更便捷的集群运维能力 、更专业的资源治理 、 更友好的运维生态
前言
本篇文章,我们开始来分析分析Kafka的
Controller部分的源码,Controller 作为 Kafka Server 端一个重要的组件,它的角色类似于其他分布式系统 Master 的角色,跟其他系统不一样的是,Kafka 集群的任何一台 Broker 都可以作为 Controller,但是在一个集群中同时只会有一个 Controller 是 alive 状态。Controller 在集群中负责的事务很多,比如:集群 meta 信息的一致性保证、Partition leader 的选举、broker 上下线等都是由 Controller 来具体负责。
源码分析
老样子,我们还是先来撸一遍源码之后,再进行总结 如果觉得阅读源码解析太枯燥,请直接看 源码总结及其后面部分
1.源码入口KafkaServer.startup
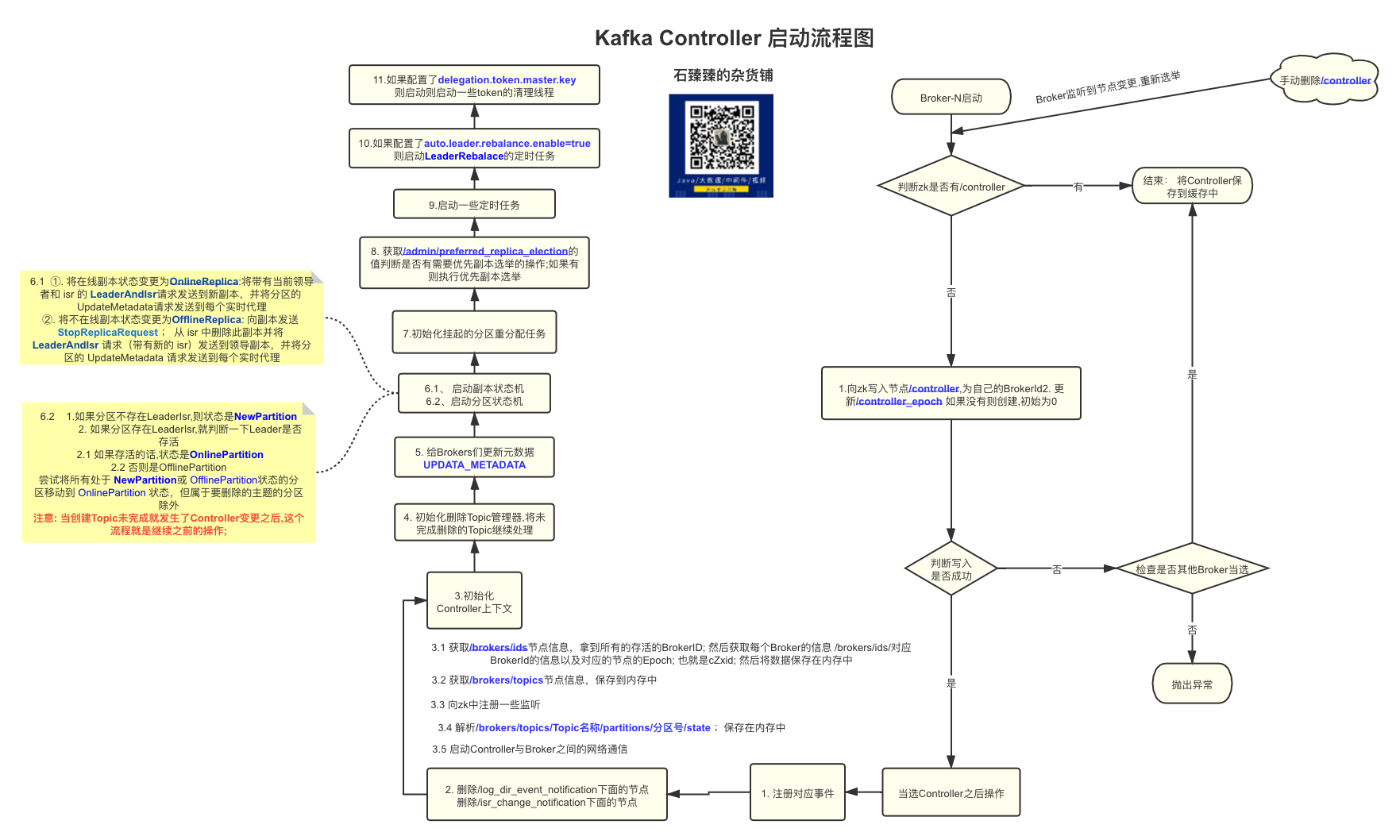
我们在启动kafka服务的时候,最开始执行的是KafkaServer.startup方法; 这里面包含了kafka启动的所有流程; 我们主要看Controller的启动流程
1 | def startup(): Unit = { |
2. kafkaController.startup() 启动
1 | /** |
zkClient.registerStateChangeHandler注册一个StateChangeHandler状态变更处理器; 有一个mapstateChangeHandlers来维护这个处理器列表; 这个类型的处理器有下图三个方法,可以看到我们这里实现了beforeInitializingSession和afterInitializingSession方法,具体调用的时机,我后面再分析(监听zk的数据变更)6017ControllerEventManager是Controller的事件管理器; 里面维护了一个阻塞队列queue; 这个queue里面存放的是所有的Controller事件; 按顺序排队执行入队的事件; 上面的代码中eventManager.put(Startup)在队列中放入了一个Startup启动事件; 所有的事件都是集成了ControllerEvent类的6419- 启动事件管理器, 从待执行事件队列
queue中获取事件进行执行,刚刚不是假如了一个StartUp事件么,这个事件就会执行这个事件
3. ControllerEventThread 执行事件线程
eventManager.start() 之后执行了下面的方法
1 | class ControllerEventThread(name: String) extends ShutdownableThread(name = name, isInterruptible = false) { |
val dequeued = queue.take()从待执行队列里面take一个事件; 没有事件的时候这里会阻塞dequeued.process(processor)调用具体事件实现的process方法如下图, 不过要注意的是这里使用了CountDownLatch(1), 那肯定有个地方调用了processingStarted.await()来等待这里的process()执行完成;上面的startUp方法就调用了; 11386
4. processStartup 启动流程
启动Controller的流程
1 | private def processStartup(): Unit = { |
注册
ZNodeChangeHandler节点变更事件处理器,在mapzNodeChangeHandlers中保存了key=/controller;value=ZNodeChangeHandler的键值对; 其中ZNodeChangeHandler处理器有如下三个接口 12990然后向zk发起一个
ExistsRequest(/controller)的请求,去查询一下/controller节点是否存在; 并且如果不存在的话,就注册一个watch监视这个节点;从下面的代码可以看出 13305选举; 选举的过程其实就是几个Broker抢占式去成为Controller; 谁先创建
/controller这个节点; 谁就成为Controller; 我们下面仔细分析以下选择
5. Controller的选举elect()
1 | private def elect(): Unit = { |
- 去zk上获取
/controller节点的数据 如果没有就赋值为-1 - 如果获取到了数据说明已经有Controller注册成功了;直接结束选举流程
- 尝试去zk中写入自己的Brokerid作为Controller;并且更新Controller epoch
- 获取zk节点
/controller_epoch, 这个节点是表示Controller变更的次数,如果没有的话就创建这个节点(持久节点); 起始controller_epoch=0ControllerEpochZkVersion=0 - 向zk发起一个
MultiRequest请求;里面包含两个命令; 一个是向zk中创建/controller节点,节点内容是自己的brokerId;另一个命令是向/controller_epoch中更新数据; 数据+1 ; - 如果写入过程中抛出异常提示说节点已经存在,说明别的Broker已经抢先成为Controller了; 这个时候会做一个检查
checkControllerAndEpoch来检查是不是别的Controller抢先了; 如果是的话就抛出ControllerMovedException异常; 抛出了这个异常之后,当前Broker会尝试的去卸任一下Controller的职责; (因为有可能他之前是Controller,Controller转移之后都需要尝试卸任一下)
- 获取zk节点
- Controller确定之后,就是做一下成功之后的事情了
onControllerFailover
6. 当选Controller之后的处理 onControllerFailover
进入到KafkaController.onControllerFailover
1 | private def onControllerFailover(): Unit = { |
把事件
BrokerChange、TopicChange、TopicDeletion、LogDirEventNotification对应的handle处理器都维护在 map类型zNodeChildChangeHandlers中把事件
ReplicaLeaderElection、ZkPartitionReassignment对应的handle处理器都维护在 map类型zNodeChildChangeHandlers中删除zk中节点
/log_dir_event_notification下的所有节点删除zk中节点
/isr_change_notification下的所有节点初始化Controller的上下文对象
initializeControllerContext()- 获取
/brokers/ids节点信息,拿到所有的存活的BrokerID; 然后获取每个Broker的信息/brokers/ids/对应BrokerId的信息以及对应的节点的Epoch; 也就是cZxid; 然后将数据保存在内存中 - 获取
/brokers/topics节点信息;拿到所有Topic之后,放到MappartitionModificationsHandlers中,key=topicName;value=对应节点的PartitionModificationsHandler; 节点是/brokers/topics/topic名称;最终相当于是在事件处理队列queue中给每个Topic添加了一个PartitionModifications事件; 这个事件是怎么处理的,我们下面分析 - 同时又注册一下上面的
PartitionModificationsHandler,保存在mapzNodeChangeHandlers中; key=/brokers/topics/Topic名称,Value=PartitionModificationsHandler; 我们上面也说到过,这个有个功能就是判断需不需要向zk中注册watch; 从下图的代码中可以看出,在获取zk数据(GetDataRequest)的时候,会去zNodeChangeHandlers判断一下存不存在对应节点key;存在的话就注册watch监视数据27433 - zk中获取
/brokers/topics/topic名称所有topic的分区数据; 保存在内存中 - 给每个broker注册broker变更处理器
BrokerModificationsHandler(也是ZNodeChangeHandler)它对应的事件是BrokerModifications; 同样的zNodeChangeHandlers中也保存着对应的/brokers/ids/对应BrokerId同样的watch监控;并且mapbrokerModificationsHandlers保存对应关系 key=brokerIDvalue=BrokerModificationsHandler - 从zk中获取所有的topic-partition 信息; 节点:
/brokers/topics/Topic名称/partitions/分区号/state; 然后保存在缓存中controllerContext.partitionLeadershipInfo28106 controllerChannelManager.startup()这个单独开了一篇文章讲解,请看【kafka源码】Controller与Brokers之间的网络通信, 简单来说就是创建一个map来保存于所有Broker的发送请求线程对象RequestSendThread;这个对象中有一个 阻塞队列queue; 用来排队执行要执行的请求,没有任务时候回阻塞; Controller需要发送请求的时候只需要向这个queue中添加任务就行了
- 获取
初始化删除Topic管理器
topicDeletionManager.init()- 读取zk节点
/admin/delete_topics的子节点数据,表示的是标记为已经删除的Topic - 将被标记为删除的Topic,做一些开始删除Topic的操作;具体详情情况请看【kafka源码】TopicCommand之删除Topic源码解析
- 读取zk节点
sendUpdateMetadataRequest给Brokers们发送UPDATA_METADATA更新元数据的请求,关于更新元数据详细情况 【kafka源码】更新元数据UPDATA_METADATA请求源码分析replicaStateMachine.startup()启动副本状态机,获取所有在线的和不在线的副本; ①. 将在线副本状态变更为OnlineReplica:将带有当前领导者和 isr 的LeaderAndIsr请求发送到新副本,并将分区的UpdateMetadata请求发送到每个实时代理 ②. 将不在线副本状态变更为OfflineReplica:向副本发送 StopReplicaRequest ; 从 isr 中删除此副本并将 LeaderAndIsr 请求(带有新的 isr)发送到领导副本,并将分区的 UpdateMetadata 请求发送到每个实时代理。 详细请看 【kafka源码】Controller中的状态机partitionStateMachine.startup()启动分区状态机,获取所有在线的和不在线(判断Leader是否在线)的分区;- 如果分区不存在
LeaderIsr,则状态是NewPartition - 如果分区存在
LeaderIsr,就判断一下Leader是否存活 2.1 如果存活的话,状态是OnlinePartition2.2 否则是OfflinePartition - 尝试将所有处于
NewPartition或OfflinePartition状态的分区移动到OnlinePartition状态,但属于要删除的主题的分区除外
PS:如果之前创建Topic过程中,Controller发生了变更,Topic创建么有完成,那么这个状态流转的过程会继续创建下去; 【kafka源码】TopicCommand之创建Topic源码解析 关于状态机 详细请看 【kafka源码】Controller中的状态机
- 如果分区不存在
initializePartitionReassignments初始化挂起的重新分配。这包括通过/admin/reassign_partitions发送的重新分配,它将取代任何正在进行的 API 重新分配。【kafka源码】分区重分配 TODO..topicDeletionManager.tryTopicDeletion()尝试恢复未完成的Topic删除操作;相关情况 【kafka源码】TopicCommand之删除Topic源码解析从
/admin/preferred_replica_election获取值,调用onReplicaElection()尝试为每个给定分区选举一个副本作为领导者 ;相关内容请看【kafka源码】Kafka的优先副本选举源码分析;kafkaScheduler.startup()启动一些定时任务线程如果配置了
auto.leader.rebalance.enable=true,则启动LeaderRebalace的定时任务;线程名auto-leader-rebalance-task如果配置了
delegation.token.master.key,则启动一些token的清理线程
7. Controller重新选举
当我们把zk中的节点/controller删除之后; 会调用下面接口;进行重新选举
1 | private def processReelect(): Unit = { |
源码总结

 微信
微信




石臻臻的杂货铺
Java/大数据/中间件/教学视频